by Scotty Salamoff, Geophysical Advisor and Project QA Lead at Bluware
What is a ‘Black Box’?
As known to many of us, a black box is a crashworthy electronic device that can provide vital information in accident investigations.
In the context of oil and gas exploration, ‘black box’ also has a long history, usually promoted by skeptical characters. You can think of the old ‘dousers’ who used willow sticks to predict where water or oil was. Then in the ‘60’s and ‘70’s when geophysical techniques became more sophisticated, there were many people who purported to have ‘magic boxes’ that they would not share the contents as it was a ‘big secret’.
In the world of software, black box testing is a method of software testing that examines the functionality of an application without peering into its internal structures or workings. For instance, the tester is aware that a particular input returns a certain, invariable output, but is not aware of how the software produces the output in the first place.
Deep learning tools (a subfield of machine learning) are now being experimented with more often by the energy industry to generate results that aid in cost-sensitive decision-making.
Scientists who use deep learning tools with the ‘black box method’ may not have a complete understanding of how the results were generated or have any sort of quantitative quality control (QC) over the results.
The Black Box Deep Learning Approach
The common black box approach in deep learning uses a neural network that has been trained on unknown data and is offered as a processing step, essentially telling the scientist to “put your seismic data in here, trust us and we will create an answer for you.”
I emphasize “trust us” because that’s exactly what you’re doing with this approach. You must rely on a network that has been trained on data that you have not seen, created with a set of unknown biases, and therefore something you have no control over.
Basic parameterization exposed to scientists in these tools gives the illusion of network control without really ceding any significant control at all. Processing times can be on the order of days or weeks, and scientists can only supply feedback to the network once the training is complete at which point training will need to run again from scratch.
In the context of geoscience, there is variability in seismic data quality due to vintage, geologic environment, or both. It is unreasonable to assume a network trained in one part (or parts) of the world by interpreters with varying levels of skills and expertise will work where you need it to.
These training datasets may contain inaccurate or inappropriate labels which could translate to erroneous predictions within your area of interest. In fact, to blindly trust the outputs of tools using a black box approach could have a very negative impact on the results because the learning process is hidden from you, the expert.
Most of these black box tools and processes require scientists to generate a full result before modifying weights, biases, or the training sets for the network, making them highly inefficient for long-term adaptation.
The Interactive Deep Learning Approach
Bluware is pioneering the concept of ‘interactive deep learning’, wherein the scientist remains in the figurative ‘driver’s seat’ and steers the network as it learns and adapts. The adjustment and optimization of training set information provides immediate feedback to the network, which in-turn adjusts weights and biases accordingly in real-time. The result removes the shrouding veil of the black box and exposes the deep learning tools to the user interactively in a familiar, scientific context.
It is a regional, data-specific approach that focuses on creating the best learning model for the data you are working with. The idea is to start with a blank, untrained network and train it while labeling to identify any feature of interest. This approach is not limited to salt or faults, but can also be used to capture shallow hazards, injectites, channels, bright spots, and more. This flexibility allows you, the expert, to explore the myriad of possibilities and alternative interpretations within your area of interest.
This labeling process differs from the traditional interpretation process in one major way: labels should only be placed precisely where the features of interest are visible, and never where our scientific minds want to extend or propagate them.
Interactive Deep Learning Applied in Geoscience
Take for example in the geoscience images below, which highlights the difference between a label set and an interpretation using an obvious fault interrupted by a thick shale sequence (Figure 1).
While the interpretation of this feature would include the shale section itself, the correct labeling strategy for adding meaningful information to the training set would be to label the fault where it is clearly imaged and omit the shale section at the beginning of the training cycle. The main reason for this is to keep the initial training set as clean and uncorrupted as possible.
The network will predict the presence of the fault through this area (inference) and the expert can reinforce this inference by accepting it using it as additional training or ignoring it, in which case it will be removed in subsequent training.
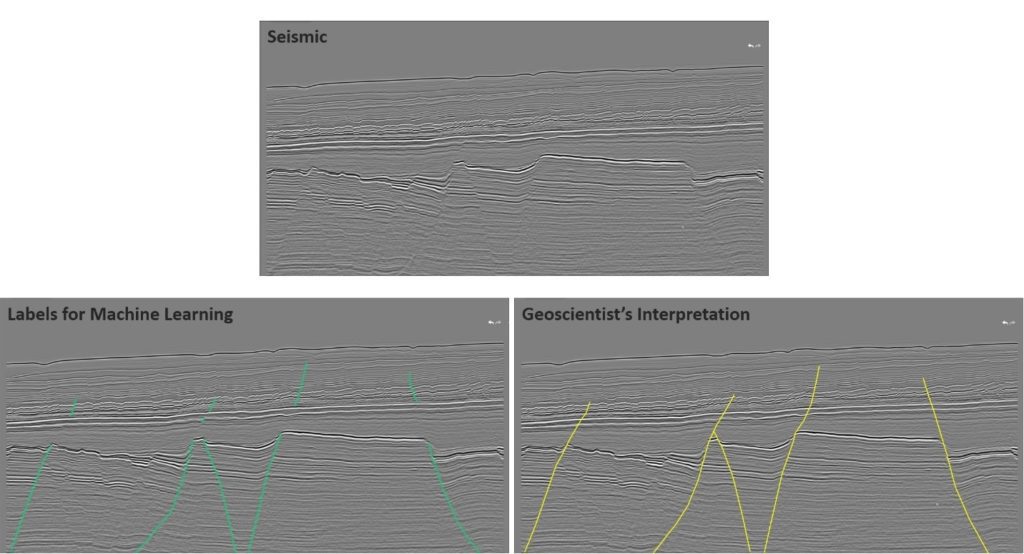 Figure 1: The difference between labeling a fault for deep learning (left) and providing a fault interpretation (right) (Bonaventure 3D seismic survey located on the northwestern shelf of Australia; dataset courtesy of the Australian Government and labels courtesy of Bluware Corp.).
Figure 1: The difference between labeling a fault for deep learning (left) and providing a fault interpretation (right) (Bonaventure 3D seismic survey located on the northwestern shelf of Australia; dataset courtesy of the Australian Government and labels courtesy of Bluware Corp.).
It is this simple application of live, iterative reinforcement learning that makes the interactive approach unique.
Interpreters are no longer restricted to what exists inside the black box. By exposing the figurative knobs and buttons of the network to the scientist, a solid and transferrable product can be generated in a fraction of the time that it takes black box approaches, which take days or even weeks to process. Creating and optimizing the training set interactively allows scientists to exert control over what the network is looking for and where in the data set it looks for it.
By modifying and building on the initial label set, the scientist is simultaneously perfecting the input information and generating a mental image of what the earth model will look like.
We’re Scientists, Not Computers
The interactive approach makes deep learning tools accessible to scientists in a context that they are familiar with. While you are labeling and training, you don’t have to step away from your work or switch to other tasks, therefore increasing productivity. The time it takes to go from an uninterpreted data volume to a working, coherent model can be cut from months to days, or in some cases to just a few hours.
Deep learning is being used to reduce the time taken to deliver interpretations. If the results aren’t accurate, the outcome could be catastrophic when it comes to drilling a well. Having greater trust in the process will give exploration companies the confidence in the results, and that is not possible with a black box approach.
The predictions from these models are often used to make critical decisions on real projects, such as spudding a well. The precise placement of these wells can carry substantial environmental, financial, and operational risks. Therefore, why trust a nebulous black box approach, when the expert can have complete control on the learning process and guide their model?
Bluware InteractivAI enables you to take control of deep learning applied interpretation by applying the interactive approach. Stop putting your trust in black box deep learning. After all, we’re scientists, not computers.