Tanmoy Palit, Cloud HPC Architect | Technical Team Lead
If you are considering moving petabytes of seismic data into cloud-based object storage, you should aim to run your High-Performance Computing (HPC) workflows without moving that data back on-premises (on-prem).
Not only are on-prem data centers less flexible in terms of scalability, but they are expensive.
- Initial investment is substantial (usually CAPEX).
- Cluster utilization is sub-optimal and not scalable upwards or downwards.
- Hardware upgrades are both time-consuming and expensive.
Consider building cloud-native HPC services which not only enable access to the seismic data in the cloud, but also optimize the cost.
Things to keep in mind:
Microservice Architecture
This is nothing new here, but it is very important to build container-based (e.g., Docker) microservices which are loosely coupled and scalable. This will automatically put you on the right track to become cloud-native.
It also allows the system to be built using open-source APIs and provides flexibility to choose the best tools for the problem at hand.
When building HPC services, you should always consider using distributed databases, queues, and caches which are open-source and highly scalable.
REST Based
If you are trying to build a HPC system for interactive seismic data processing, then RESTful APIs are the way to go as they are stateless, support all data formats, and can be easily integrated to any other system.
When it comes to scalability and portability, REST is the best option. Almost every programming language has support for REST (if not, consider moving to a language that supports it as there are several advantages to using REST).
Design the REST endpoints using OpenAPI specs (OAS) which will allow automatic client code generation and documentation.
If the system needs to be bi-directionally interactive, use WebSockets. Modern web frameworks like FastAPI supports both REST interfaces and WebSocket.
Another good alternative to REST would be to use GraphQL.
Dynamic Scalability with High Fault Tolerance
Whether you have an interactive or batch processing system, the best way to optimize cost in the cloud is to build a system which can dynamically scale with a high fault tolerance.
The cloud offers unlimited resources which come in many flavors. If you want resources that will never fail, they are very expensive. On the other hand, if your system can be deployed with something like a spot instance, this will translate into savings.
The clusters need to be designed to shrink and expand based on the workload which is standard in the cloud environment.
Everything boils down to how stateless your components are. Traditional HPC clusters for seismic data usually pre-load data in the cluster and is an anti-pattern for designing a stateless system. You need to design and deploy your services in ways where, if an instance of service goes down, another can take over quickly enough so that the overall performance of the system is never compromised.
So, we need to move from pre-loading data to accessing seismic data only when it is required directly from cloud-based object storages.
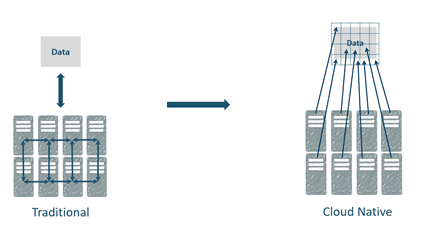
Instead of distributing data, you can distribute your workflows across all nodes and access only parts of data required for computation. Distributed seismic storage format like should be used to achieve required performance.
If a system needs to cache anything, then use a distributed cache like Redis or Memcached instead of saving the state on the resources.
Portability (Cloud Agnostic)
Finally, the system needs to be portable between multiple cloud providers to avoid lock-in. Build your deployment pipeline targeting multiple cloud environments.
The first step to achieve this is by building container-based services. Next, we need to pay attention to the deployment components. As always, open-source is our best friend here. You should use Kubernetes for deploying the containers as all cloud providers have out of the box support for it.
When selecting third parties, such as databases and caches, check out multiple cloud providers for compatibility. For example. AWS and Azure both have MongoDB, MySQL, or Redis compatible services.
Conclusion:
Moving petabytes of seismic data to cloud storage is the beginning of the journey. We have all probably heard this before – Move compute to data as moving data to compute can be very expensive.
So, it is time to move away from the legacy architectures, re-evaluate existing HPC workflows and move them to the cloud – natively.